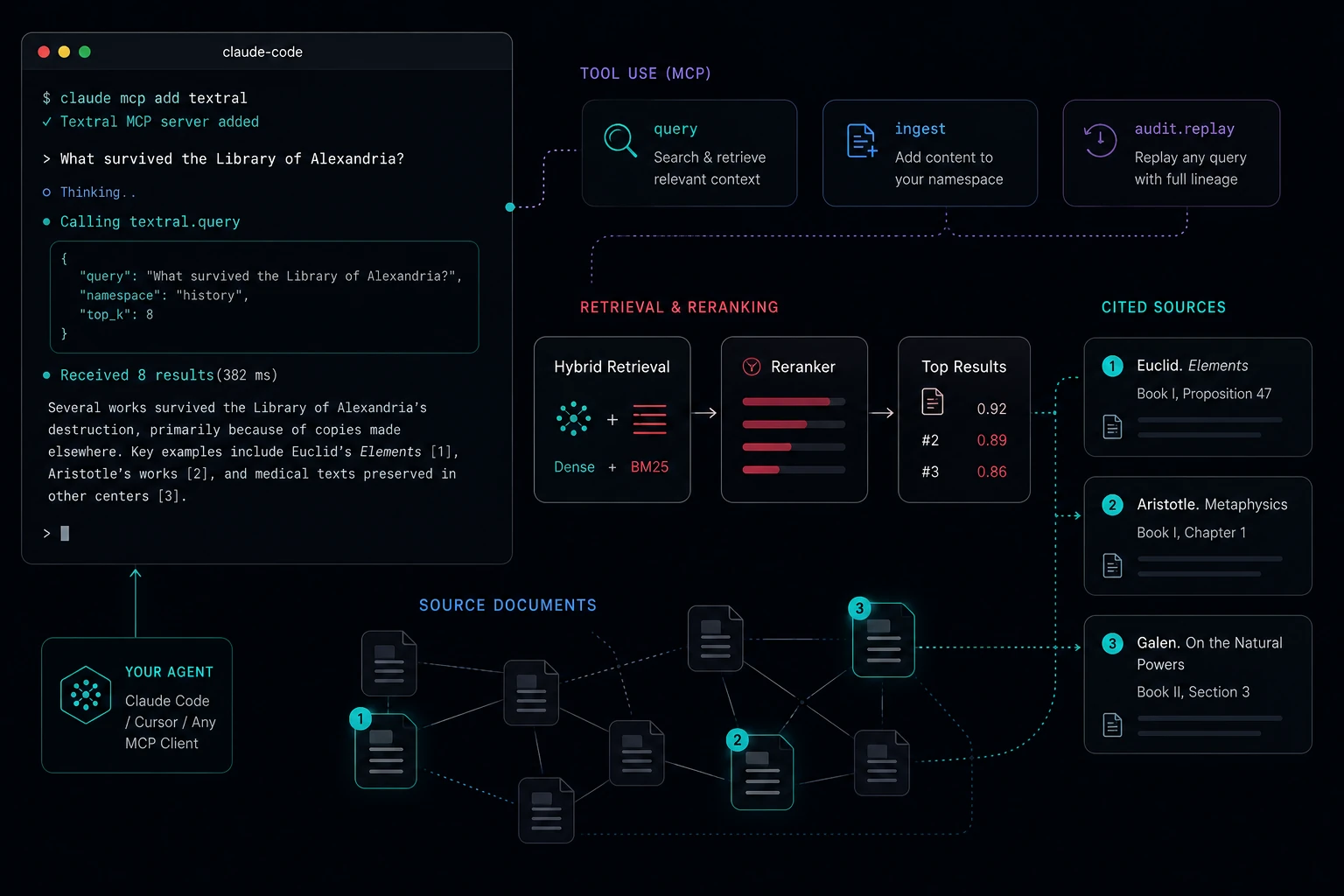
MCP-native by default
Your AI agent calls Textral directly — no glue code, no wrappers. One install, multi-profile addressing for stage and prod, every tool surfaced.
Hybrid retrieval, audit-first, MCP-native. Run it on Cloudflare or self-host on your own infra — same packages, same contracts.
No credit card. Free during beta.
What you get
Your AI agent calls Textral directly — no glue code, no wrappers. One install, multi-profile addressing for stage and prod, every tool surfaced.
Dense + BM25 + reranker out of the box. Per-namespace dimension locking catches the silent embedding mismatches other services let you ship into production.
Every query is a forensically-replayable event with retrieval lineage, citation integrity, dropped-citation tracking, and per-arm error surfacing.
Hosted on Cloudflare, or self-hosted on your own infra. Same packages. Same contracts. No fork, no migration story.
The audit story
When retrieval quality silently degrades, most teams find out from a user complaint. Textral surfaces it the second it happens.
Every query returns a query_event_id
you can replay weeks later. Full retrieval lineage: which arm
fired, what scored, what was reranked, what got cited, what got
dropped. Per-arm error messages when an arm degrades. Citation
integrity validated against the chunks you actually retrieved.
We shipped a real production fix on day two of building Textral because the audit caught a silent dimension-mismatch bug nothing else would have. The kind of bug that turns into "our retrieval just got worse, no one knows why" three months later.
{
"query_event_id": "qev_01KR39M0YHK6KJ14S7QXKVWWQW",
"answer": "The library's legacy endures through the texts that were copied and disseminated…",
"citations": [
{ "n": 1, "chunk_id": "chk_…", "section_path": "/chapter-six-what-survived" },
{ "n": 2, "chunk_id": "chk_…", "section_path": "/chapter-three-the-founding" },
{ "n": 3, "chunk_id": "chk_…", "section_path": "/chapter-four-the-scholars" },
{ "n": 4, "chunk_id": "chk_…", "section_path": "/chapter-five-the-decline" }
],
"audit": {
"retrieval_status": "full",
"dense_candidates_returned": 4,
"sparse_candidates_returned": 8,
"candidates_returned": 8,
"reranker": { "provider": "voyage", "model": "rerank-2", "executed": true },
"citation_integrity": "valid",
"dropped_citations": []
}
}
Code-first proof
claude mcp add textral --scope user -- npx -y @textral/mcpimport { TextralClient } from "@textral/sdk";
const client = new TextralClient({ profile: "hosted-prod" });
// Ingest
await client.documents.ingest({
namespace: "narrative",
filename: "alexandria.md",
content: alexandriaText,
});
// Query with citations
const { answer, citations, audit } = await client.query({
namespace: "narrative",
query: "What survived the Library of Alexandria?",
});from textral import Client
with Client(profile="hosted-prod") as client:
# Ingest
client.documents.ingest(
namespace="narrative",
filename="alexandria.md",
content=alexandria_text,
)
# Query with citations
r = client.query(
namespace="narrative",
query="What survived the Library of Alexandria?",
)
answer, citations, audit = r["answer"], r["citations"], r["audit"]curl -X POST https://api.textral.alacrity.ai/query \
-H "Authorization: Bearer $TEXTRAL_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"namespace": "narrative",
"query": "What survived the Library of Alexandria?",
"embedding": { "provider": "openai", "model": "text-embedding-3-large" },
"inference": { "provider": "openai", "model": "gpt-4o-mini" }
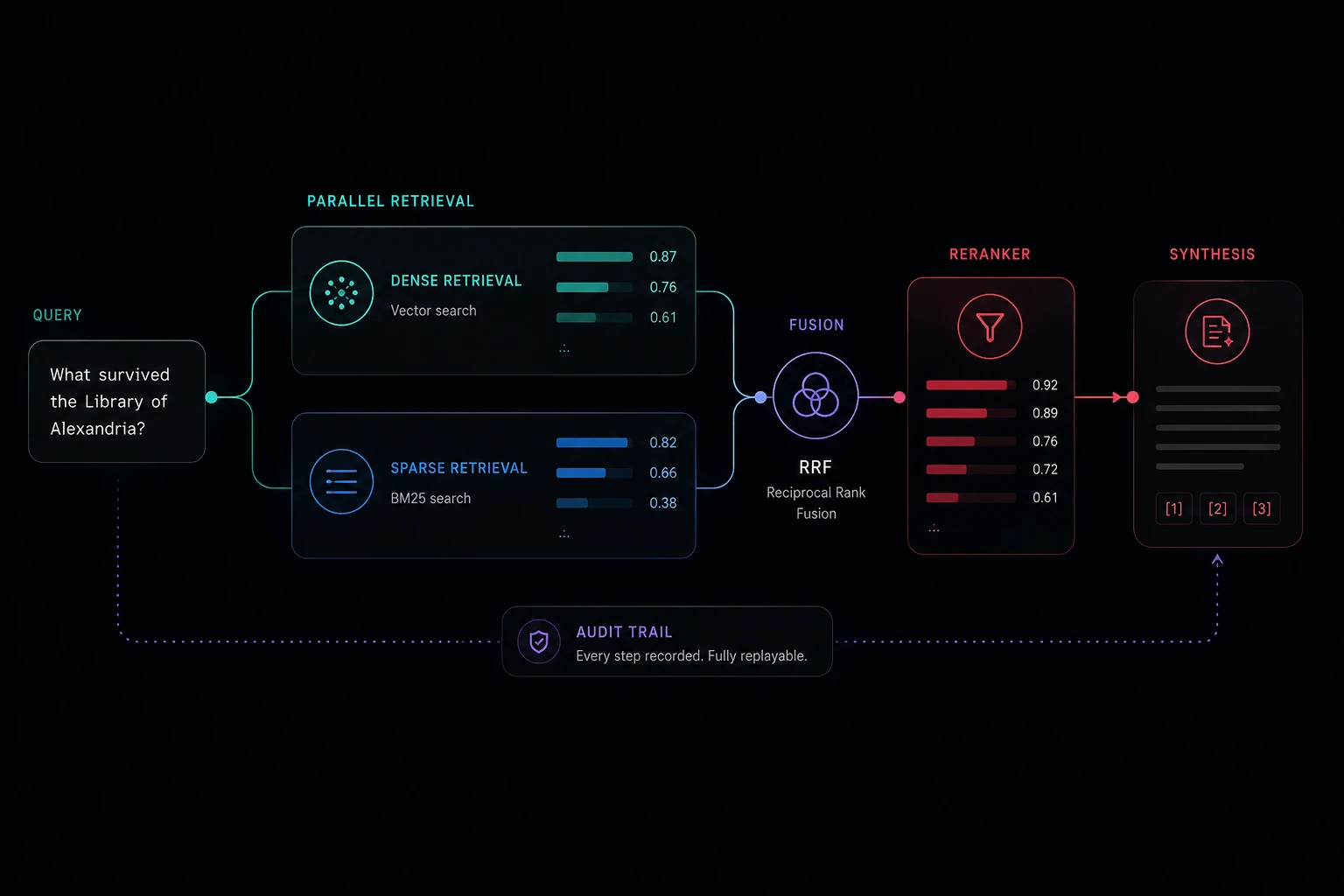
}'How it works
Ingest splits documents into section-aware chunks, embeds them with the provider you chose, indexes them in both a vector store (Cloudflare Vectorize or Pinecone) and a BM25 sparse index. Query runs both arms in parallel, fuses with reciprocal-rank fusion, reranks with Voyage, and synthesizes with the inference model you chose. Every step writes an audit row. Every audit row is replayable.
Ingest
section-aware chunks
Embed
OpenAI / Voyage / Cohere
Index
Vectorize or Pinecone + FTS5
Retrieve
dense + sparse, in parallel
Fuse · Rerank · Synthesize
RRF → Voyage → inference
Architecture diagram with the full ingest + query paths is on the roadmap. In the meantime: every step above appears in the audit object.
Deploy anywhere
The MCP profile model lets one Claude Code session talk to a hosted dev instance and a self-hosted prod instance in the same conversation. We did not bolt this on as a v2 — it's how the product was built.
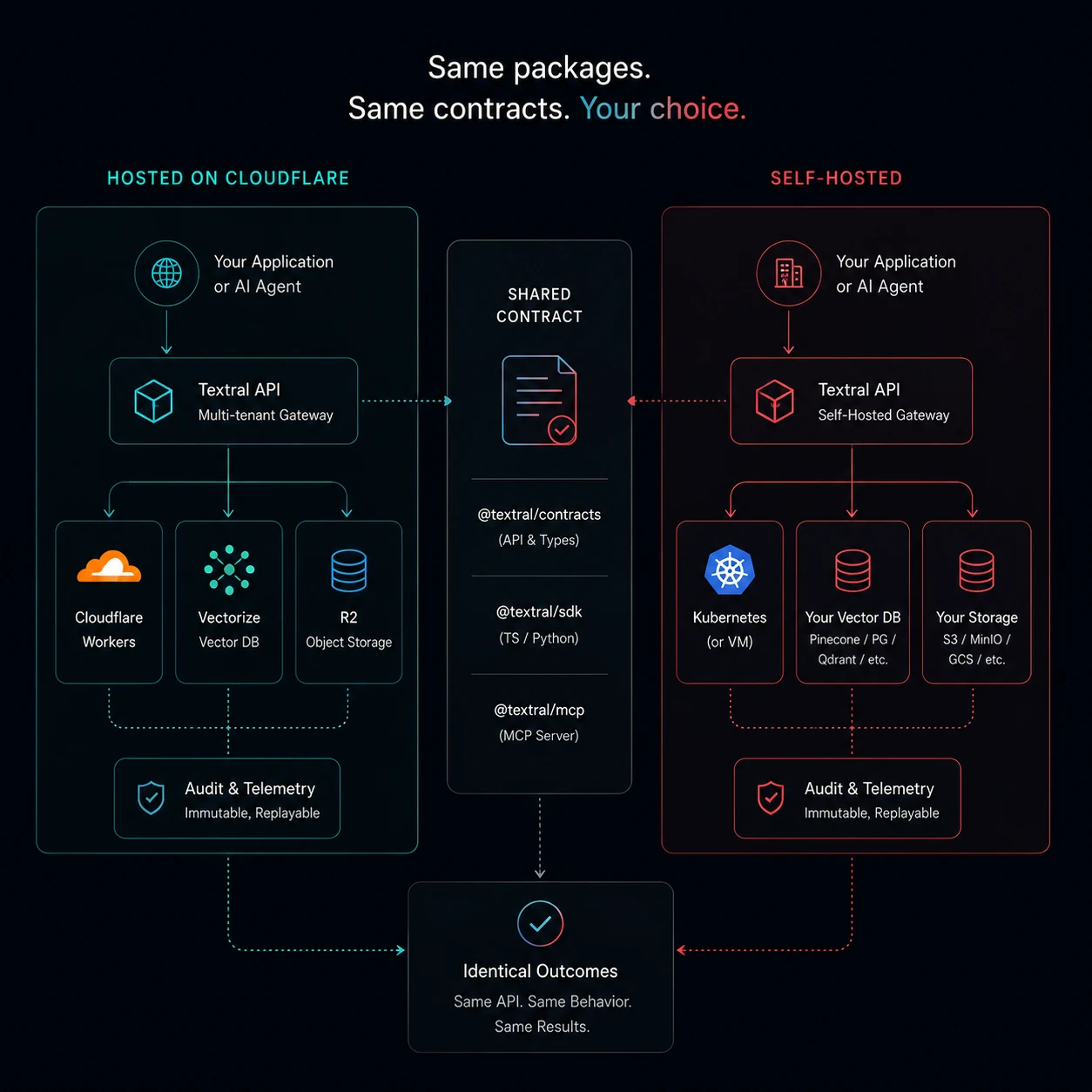
Hosted
Spin up a tenant in the sandbox, get an API key, ingest your first document. We run the workers, the database, the vector store. You bring your provider keys (OpenAI, Anthropic, Voyage, Cohere) — or use ours.
Start in the sandboxSelf-hosted
Same packages. Same contracts. Deploy @textral/api
to your own Cloudflare account or your own runtime. The MCP
server, SDKs, and audit trail work identically. No fork, no
separate codebase to maintain.
How it stacks up
If a competitor matches us on a row, we say so. If we're behind, we don't hide it. Reviewed 2026-05-08.
| Feature | Textral | Pinecone Assistant | Vectara | OpenAI File Search |
|---|---|---|---|---|
| MCP-native | — | — | — | |
| Hybrid retrieval (dense + sparse) | ||||
| Reranker in the box | — | |||
| Full audit lineage | full | |||
| Self-hostable (same packages) | — | — | — | |
| Multi-tenant API | per account | per account | per account | |
| Pluggable vector backend | locked to Pinecone | locked | locked to OpenAI | |
| BYO provider keys | — | |||
| Open-source SDK + MCP | — | — | — |
"MCP-native" means we ship a maintained MCP server as a first-class npm package, not that the competitor cannot be wrapped. Wrapping any REST API in an MCP server is possible; doing it well is not.
What's next
Public roadmap. Pull-requests welcome.
Roadmap
Public benchmark + per-namespace drift detection. nDCG@k, Recall@k, MRR — alerted when retrieval quality degrades on your corpus.
Read the specRoadmap
Multi-hop, decompose-then-synthesize. The audit captures the full hop trace, so complex questions stay debuggable.
Read the specRoadmap
Notion, GitHub, Slack, Drive, Confluence. Auto-ingest, delta-sync, source metadata for filtered queries.
Read the specRoadmap
Hosted fine-tuned rerankers on your corpus. +5–12pt nDCG over generic baselines for specialized domains.
Read the specBeta · No credit card
We're in private beta. Sandbox tenants are free; bring-your-own provider keys (OpenAI, Anthropic, Voyage, Cohere) cover inference and reranking costs.
When pricing lands, you'll see it here first — and beta tenants get advance notice and a grandfathered tier.
Spin up a tenant. Ingest your first document. Watch your agent cite it. All in under three minutes.
Free during beta. No credit card.